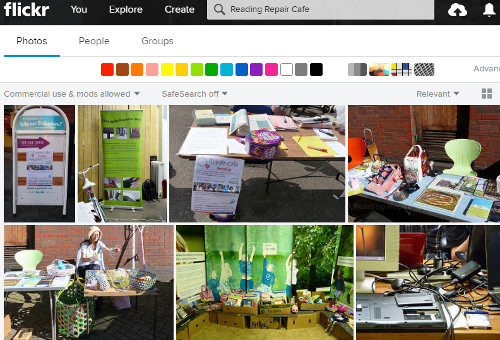
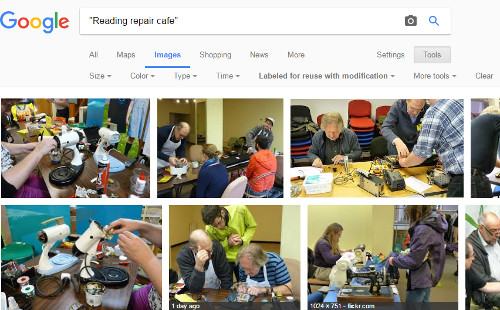
The problems start if you are researching a person, company or industry based in a country other than your own - let's use Norway as an example - or just want the latest news from that country. The trick used to be to go to the relevant country version of Google, in this case www.google.no, run your search and Google would give preference to Norwegian content. It is a great way to get alternative viewpoints on a topic and more relevant "local" information on a subject. Now, regardless of which version of Google you go to, you will see the same results tailored for your home location.
In a blog posting Making search results more local and relevant Google says:
Today, we’ve updated the way we label country services on the mobile web, the Google app for iOS, and desktop Search and Maps. Now the choice of country service will no longer be indicated by domain. Instead, by default, you’ll be served the country service that corresponds to your location. So if you live in Australia, you’ll automatically receive the country service for Australia, but when you travel to New Zealand, your results will switch automatically to the country service for New Zealand. Upon return to Australia, you will seamlessly revert back to the Australian country service.
This confirms that mobile search is what Google is concentrating on. After all it is, one assumes, where Google makes most of its money but it does not help professional researchers.
There is a way around it but it is rather long-winded. You need to go to Settings - use either the link in the bottom right hand corner of your Google home page or the one near the top of a search results page - and click on Advanced Search .
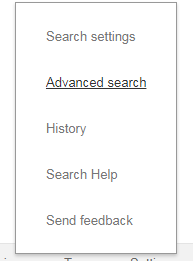
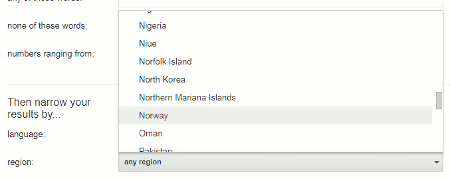
On the Advanced Search screen scroll down to “Then narrow your results by…” and use the pull down menu in the region box to select the country.
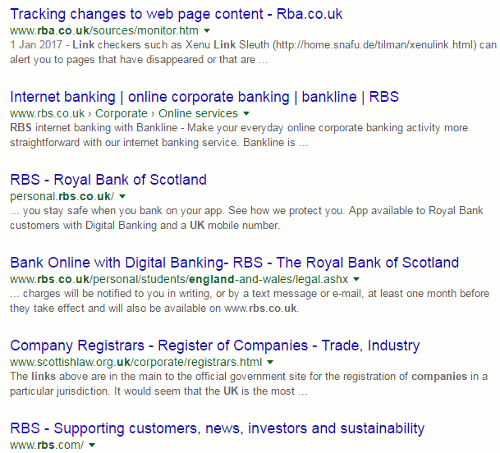
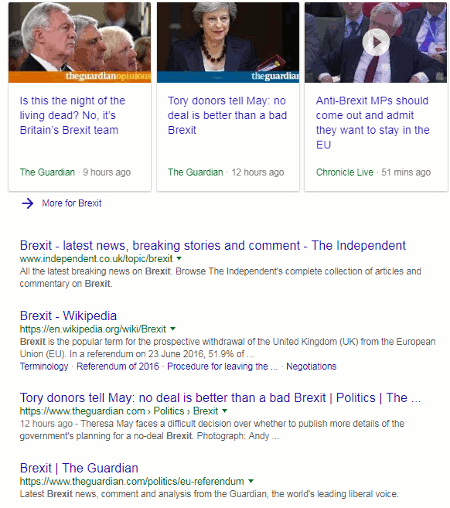
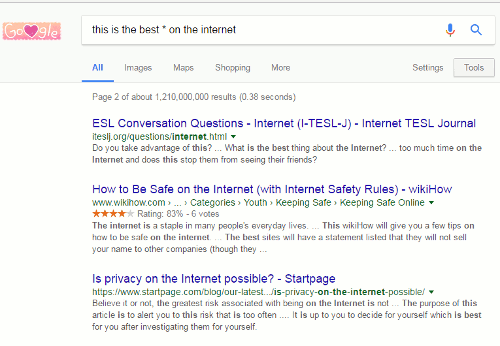
I ran a search on Brexit in google.co.uk, google.no and a few other country versions of Google. All gave me essentially the same results.
Using the region filter and selecting Norway as the country I am given the following by Google:
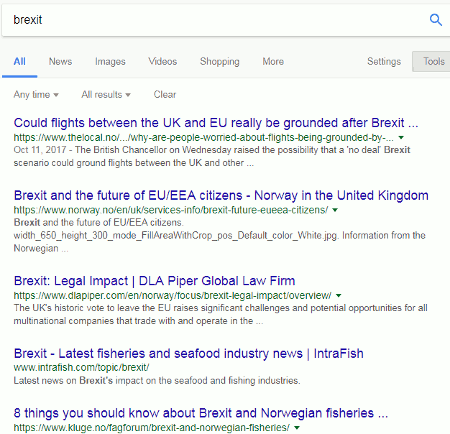
Notice, though, that Google is giving me English articles or English versions of them. Google has decided that I would prefer English articles and I have to scroll down to number 10 and beyond to see pages in Norwegian. To get a broader view of what is being said in Norway about Brexit I have to go back into settings, click on Languages and choose Norwegian/Norsk.
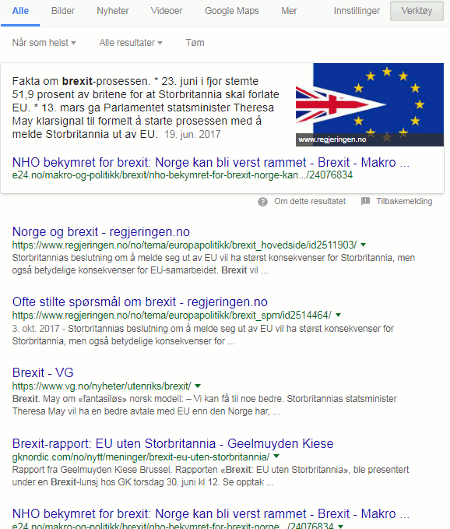
Oh - and you get slight different results if you go through a VPN and set Norway as the country.
What worries me even more is that Google could do away with the advanced search screen and the region filter with it.
Google says:
We’re confident this change will improve your Search experience, automatically providing you with the most useful information based on your search query and other context, including location.
No, Google. You have just made things more difficult for those of us who conduct serious, in-depth research. The way I feel about this change at the moment is that if you were a person I would take a baseball bat to your head!
UPDATE: In response to David Pearson's comment and reminder below.
Including a site command e.g. site:no in the search works relatively well for this particular example (Norway) and gives good but slightly different results. It will, of course, miss Norwegian sites that are registered as .com or other international domains. The amount of overlap (or lack of it) will vary depending on the country. It's another one to add to the list of strategies, which I am sure will become longer, for dealing with this problem.

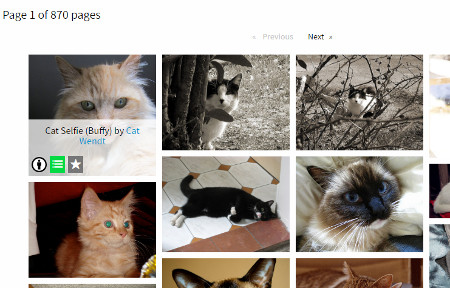
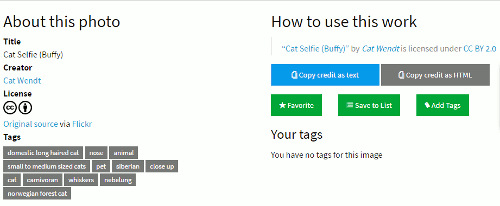
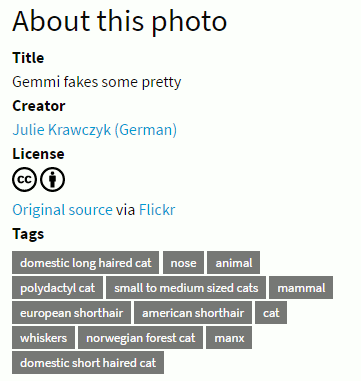
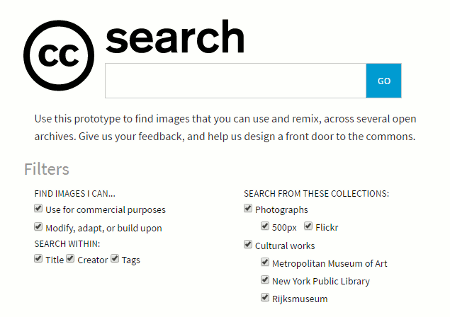 As well as search there are social features that allow you to add tags and favourites to objects, save searches, and there is a one-click attribution button that provides you with a pre-formatted text for easy attribution. There is also a list creation option. To make use of these functions you need to register, which at present can only be done via email.
As well as search there are social features that allow you to add tags and favourites to objects, save searches, and there is a one-click attribution button that provides you with a pre-formatted text for easy attribution. There is also a list creation option. To make use of these functions you need to register, which at present can only be done via email.